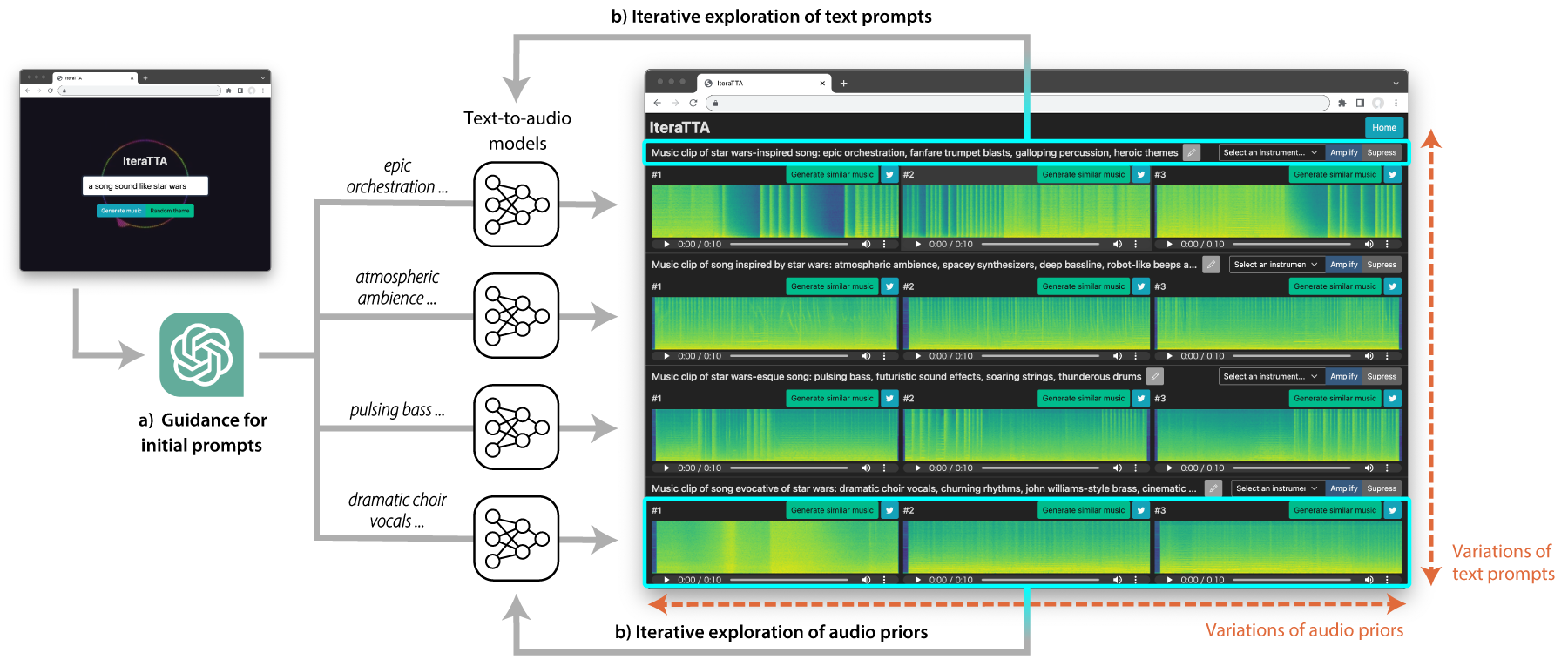
Recent text-to-audio generation techniques have the potential to allow novice users to freely generate music audio. Even if they do not have musical knowledge, such as about chord progressions and instruments, users can try various text prompts to generate audio. However, compared to the image domain, gaining a clear understanding of the space of possible music audios is difficult because users cannot listen to the variations of the generated audios simultaneously. We therefore facilitate users in exploring not only text prompts but also audio priors that constrain the text-to-audio music generation process. This dual-sided exploration enables users to discern the impact of different text prompts and audio priors on the generation results through iterative comparison of them. Our developed interface, IteraTTA, is specifically designed to aid users in refining text prompts and selecting favorable audio priors from the generated audios. With this, users can progressively reach their loosely-specified goals while understanding and exploring the space of possible results. Our implementation and discussions highlight design considerations that are specifically required for text-to-audio models and how interaction techniques can contribute to their effectiveness.

|
Hiromu Yakura and Masataka Goto: IteraTTA: An interface for exploring both text prompts and audio priors in generating music with text-to-audio models.
In Proceedings of the 24th International Society for Music Information Retrieval Conference (ISMIR), 2023. [Paper] [arXiv:2307.13005] |
This work was supported in part by JSPS KAKENHI (JP21J20353), JST ACT-X (JPMJAX200R), and JST CREST (JPMJCR20D4).